


Building RAG from Day One: It's time for Agentic RAG (Part 3)
In this technical deep dive, we'll explore the backend implementation of our Agentic RAG system. Demo and code are provided below

Demo
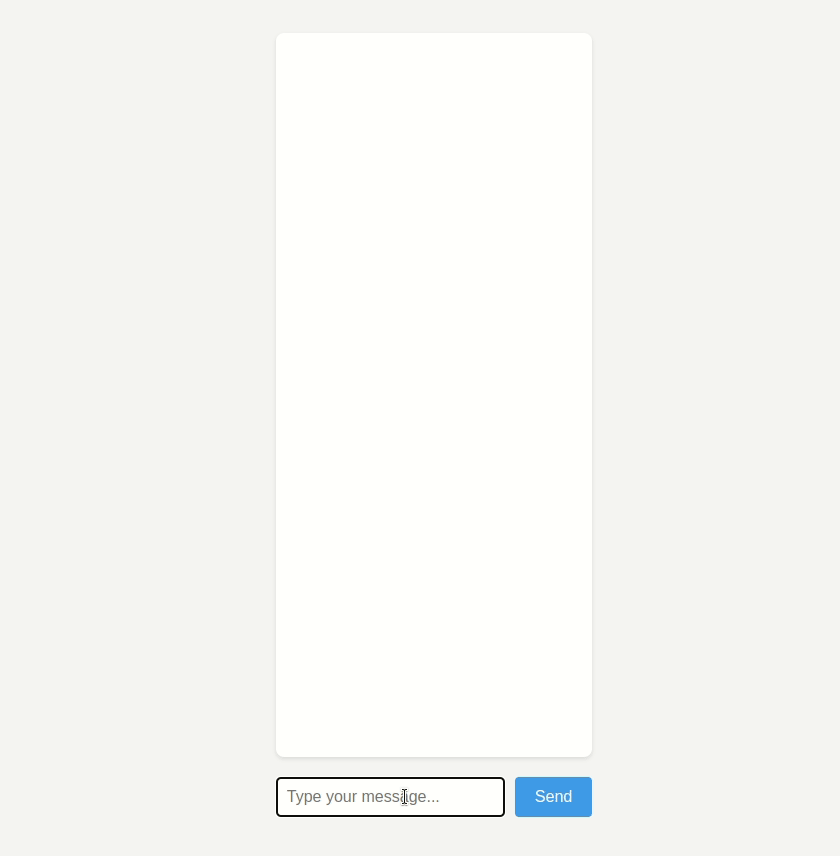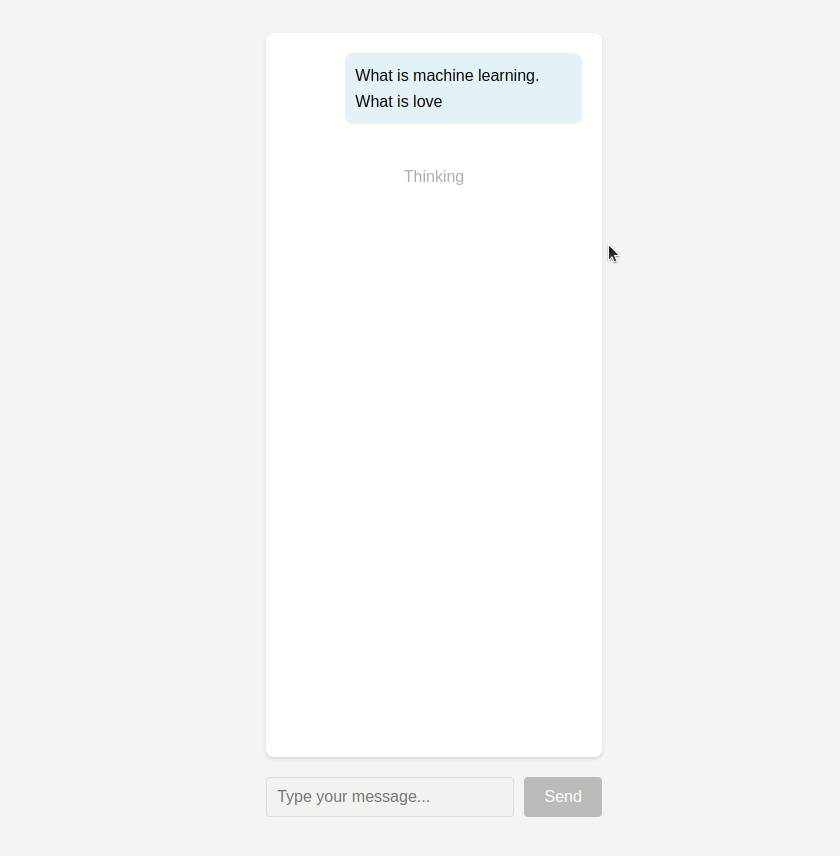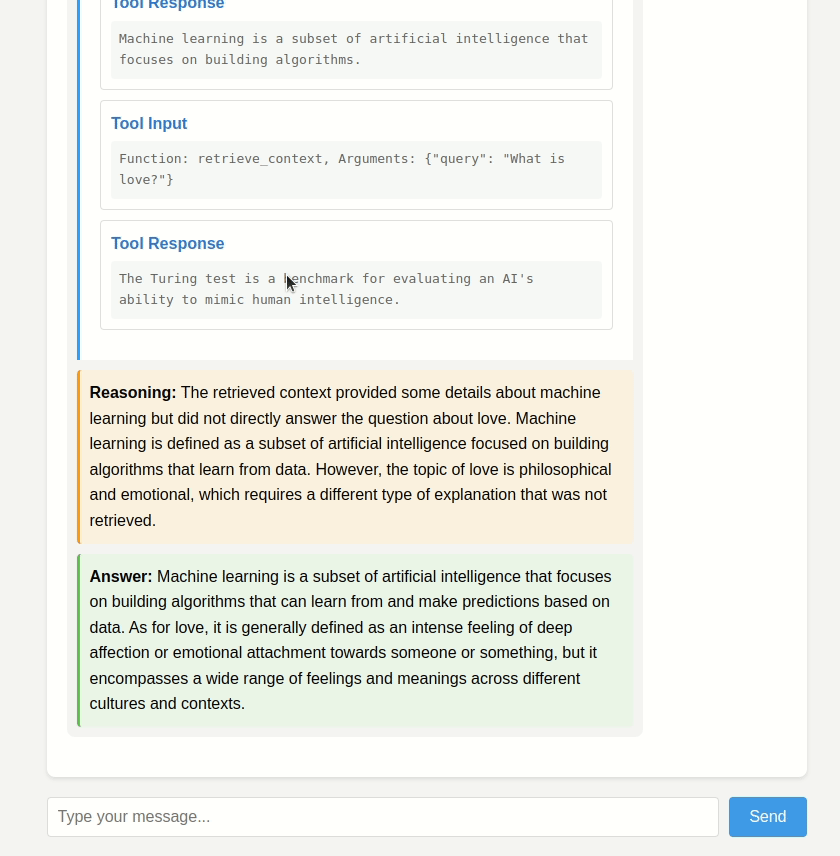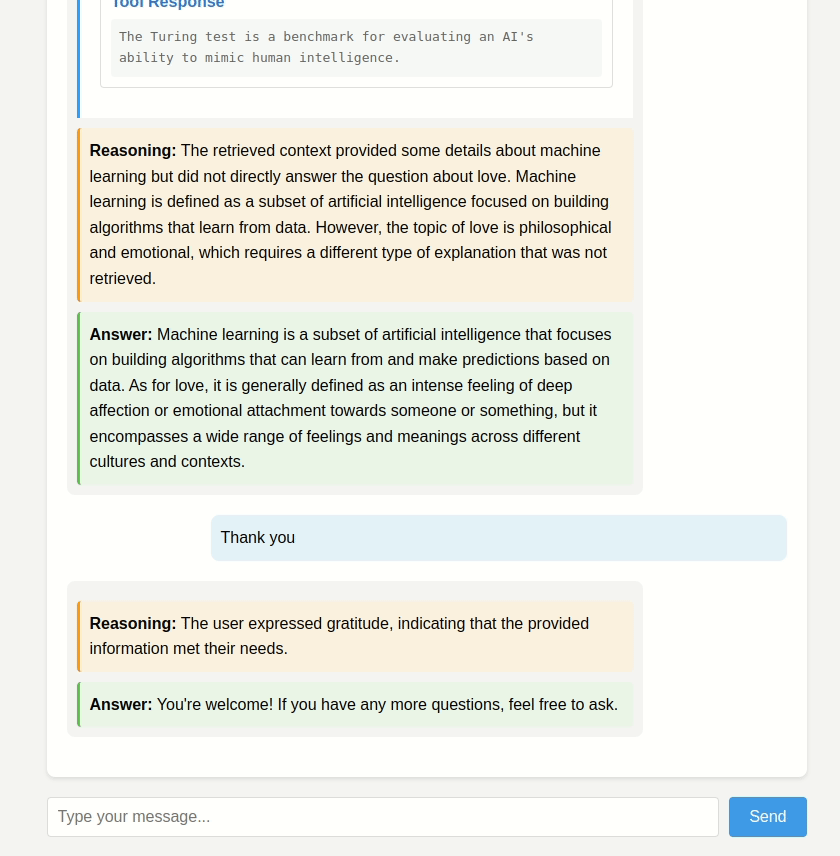
Github link: link
Backend Architecture Overview
The backend is organized into three main modules:
- `embeddings.py`: Handles text embedding operations
- `rag_engine.py`: Core RAG implementation with reasoning capabilities
- `server.py`: FastAPI server for handling requests
Let's examine each component in detail.
Text Embeddings (`embeddings.py`)
The embeddings module provides two essential functions:
```python
def cosine_similarity(vec1, vec2):
"""Calculate cosine similarity between two vectors"""
vec1 = vec1.flatten()
vec2 = vec2.flatten()
dot_product = np.dot(vec1, vec2)
magnitude1 = np.linalg.norm(vec1)
magnitude2 = np.linalg.norm(vec2)
return dot_product / (magnitude1 * magnitude2)
```This function calculates the similarity between two vectors using cosine similarity, which is crucial for finding relevant context. The cosine similarity ranges from -1 to 1, where 1 means the vectors are identical, 0 means they're orthogonal, and -1 means they're opposite.
```python
def embed_texts(texts):
"""Get embeddings for a list of texts using OpenAI's embedding model"""
response = client.embeddings.create(
model=os.getenv("OPENAI_EMBEDDING_MODEL", "text-embedding-3-small"),
input=texts
)
embeddings = [np.array(item.embedding) for item in response.data]
return np.stack(embeddings)
```The `embed_texts` function converts text into numerical vectors using OpenAI's embedding model. These vectors capture the semantic meaning of the text, making it possible to compare texts based on their content rather than just keywords.
RAG Engine (`rag_engine.py`)
The RAG Engine is the heart of our system. Let's break down its key components:
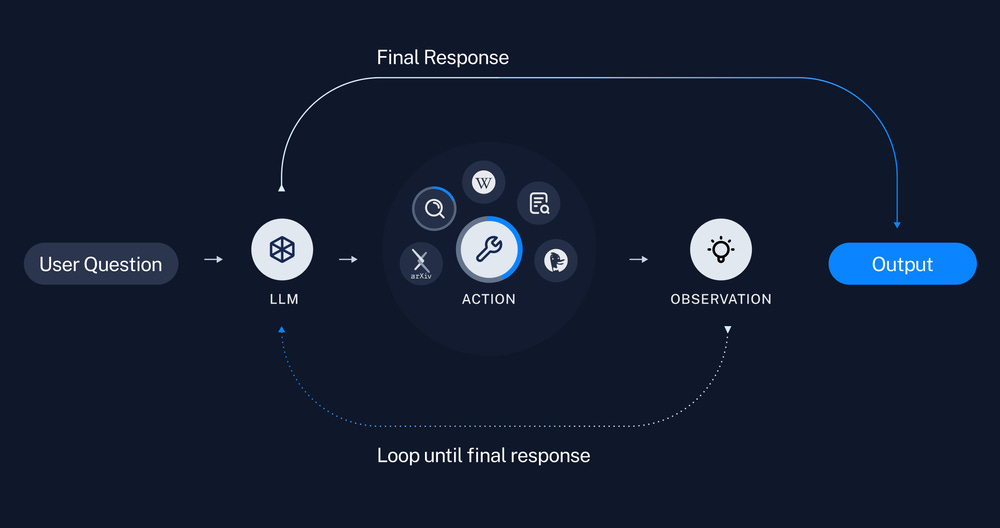
Initialization
```python
def __init__(self):
self.client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
self.model = os.getenv('OPENAI_MODEL', DEFAULT_MODEL)
self.agent_loop_limit = AGENT_LOOP_LIMIT
```The engine is initialized with OpenAI credentials and configuration settings. The `agent_loop_limit` prevents infinite loops during context retrieval.
Context Retrieval
```python
def retrieve_context(self, query: str) -> str:
data_embeddings = embed_texts(self.data)
query_embedding = embed_texts([query])[0].reshape(1, -1)
similarities = [
cosine_similarity(query_embedding, data_embedding.reshape(1, -1))
for data_embedding in data_embeddings
]
most_relevant_idx = np.argmax(similarities)
return self.data[most_relevant_idx]
```This method finds the most relevant context by:
1. Converting both the query and knowledge base texts into embeddings
2. Computing similarity scores between the query and each piece of context
3. Returning the context with the highest similarity score
Response Generation
```python
def get_response(self, query: str) -> Dict[str, Any]:
intermediate_steps = []
initial_response = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
tools=self.tools,
response_format=self.context_reasoning
)
```The response generation process:
1. Maintains a conversation history in `self.messages`
2. Uses OpenAI's function calling to dynamically retrieve context
3. Tracks intermediate steps for transparency
4. Enforces a structured response format with reasoning and final answer
FastAPI Server (`server.py`)
The server provides a RESTful API endpoint for the frontend:
```python
@app.post("/chat")
async def chat(request: ChatRequest):
try:
if not request.message.strip():
raise HTTPException(status_code=400, detail="Message cannot be empty")
response = rag_engine.get_response(request.message)
return response
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
```Key features:
- Input validation using Pydantic models
- Error handling with appropriate HTTP status codes
- CORS middleware for frontend access
- Structured JSON responses
What Makes This RAG Implementation "Agentic"?
Our implementation is "agentic" because it:
1. **Actively Reasons**: Instead of just retrieving and regurgitating context, it reasons about the relevance and application of the retrieved information.
2. **Multi-step Processing**: The system can make multiple context retrievals if needed, building up a more complete understanding of the query.
3. **Transparent Decision Making**: All intermediate steps are tracked and returned, showing how the system arrived at its final answer.
4. **Structured Output**: The response format enforces explicit reasoning, ensuring the system explains its thought process.
Conclusion
This implementation demonstrates how to build a RAG system that goes beyond simple context retrieval. By incorporating reasoning capabilities and maintaining transparency, we create a more intelligent and trustworthy system.
The code is designed to be modular and extensible. You can enhance it by:
- Adding more sophisticated context retrieval methods
- Implementing context caching for better performance
- Expanding the knowledge base with dynamic data sources
- Adding more tools for the agent to use